
如果你也和我一样,最近在研究怎么用 AI 把别人做得很好的 YouTube 视频复刻出来,那么你一定知道,有一个步骤很关键——拆解对标视频的结构和画面内容。
过去我都是一帧一帧截图,然后再拿去写提示词、做图再生视频。说实话,这活儿又慢又容易出错。但最近我发现了一个神器级的流程,可以一键获取对标视频的关键帧画面和内容提示词,整个效率直接起飞。
复刻对标视频?先理解“关键帧”是啥
“关键帧”简单说就是视频中每个场景变化开始的第一帧图像,是最能代表该场景氛围和信息量的那一张图。
比如说,一个拍地球爆炸的科幻短片,关键帧可能就会是:
- 一颗正常旋转的地球
- 卫星靠近的那一瞬间
- 地球开始裂开
- 爆炸发生的那一秒
这几张图如果你能提取出来,再倒推生成 AI 图像和文字脚本,几乎就是原视频的复刻逻辑骨架了。
普通流程太慢?AI 现在能全自动帮你搞定
过去我是怎么做的?
- 用浏览器插件或工具把 YouTube 视频下载下来
- 拖进剪映或者 PR,一个个手动找关键帧截屏
- 把这些图片拿去 ChatGPT 或者 Midjourney 拼命调 prompt
- 再把图拿去做视频合成
说实话,这种流程真的很折磨,尤其是步骤太多太容易漏,最难的是:提示词靠猜!猜不准,风格、内容全跑偏!
后来我无意中试了 Gemini 2.5,真的有点被惊到了。
Gemini 能直接把你要的全给你
你只需要做两件事:
- 把 YouTube 的链接粘进去
- 告诉它你要什么(比如“我要提取每个场景的关键帧+生成提示词”)
然后奇迹就发生了。
Gemini 会自动识别视频中的重要场景,然后每个场景挑出一张图(就是关键帧),同时还会针对那张图帮你生成AI 图生图的提示词(Prompt),比如图2和图3中显示的效果。
你甚至可以跟它说你希望最终生成什么风格的内容,比如“二次元科幻”或者“像素风视觉系”这些,它都会自动调整提示词和输出风格。
我自己测了一次,丢进去一个关于“火箭升空”的视频,它就给我提取了:
- 火箭准备发射的场景图
- 火箭喷火升空那一帧
- 穿越云层的高空镜头
- 卫星分离画面
每张图配了 prompt,甚至还自动识别了视频字幕帮我提取出内容关键词,真的让我省下了至少两个小时!


这里用到的提示词
解读一下我发你的视频,我想要你把这个视频里面所有镜头的第一个快去画面拆出来,然后再提取这个画面对应生成的提示词,注意要保留帧率,同时再将这个画面部分的AI视频的原始音声节也写出来,只注重语音发生时的动词动作,并且动作需要符合行动逻辑,以便我交给AI视频对话去制作视频。注意提取每个提示词上保持风格和动词的一致性。
格式要求,所有的镜头以及提示词的输出按照表格的格式,分别:序号,图片提示词(中文),图片提示词(英文),视频提示词(中文),视频提示词(英文)。用 Gemini 纯粹分析要点
当然了,有些人可能不是为了复刻视频,而是想搞懂对手视频到底讲了什么内容、吸引人的点在哪。
这时候 Gemini 也是一把好用的刀。
你只需要输入链接,给 Gemini 一个简单的指令:“帮我概括这条视频讲了什么”,它就能帮你整理出结构要点、主题和内容梳理。
我试着让它分析一个关于“AI生成图像对比测试”的 YouTube 视频,结果它不仅分析了每一段内容、列出测试对比项,还用 bullet point 的方式整理出哪些点是亮点,哪些地方观众反应最强。
就像图4和图5那样,它把整条视频拆成几个大块,像个 PPT 一样讲给你听。这个功能对做内容研究、剪辑复用、写笔记都超级有用。
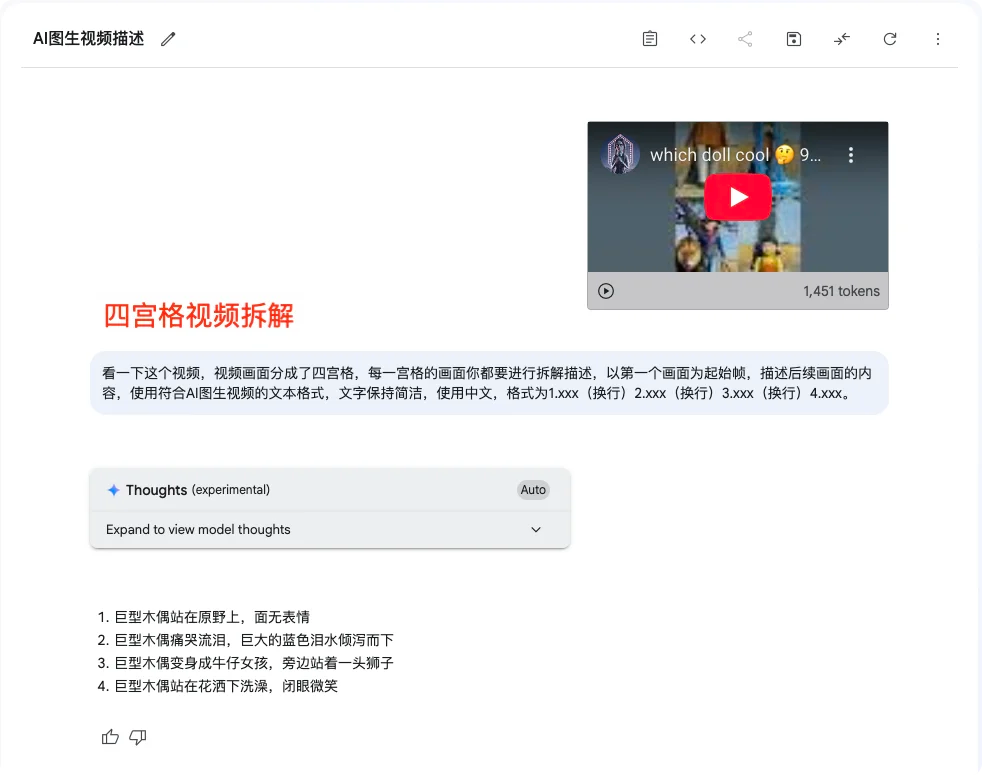

这里用到的提示词(四宫格画面拆解)
看一下这个视频,视频画面分成了四宫格,每一宫格的画面你都要进行拆解描述,以第一个画面为起帧,描述后续画面的内容,使用符合AI图生视频的文本格式,文字保持简洁,使用中文,格式为1.xxx(换行)2.xxx(换行)3.xxx(换行)4.xxx。写在最后
我知道很多人可能觉得:这不就分析视频嘛,哪有那么神?但我真的是亲身踩了不少坑之后,才体会到一个“一键到位”的流程有多省事。
这不仅仅是节省时间的问题,而是让你从“猜测”变成“复制成功逻辑”,尤其在短视频行业越卷越狠的今天,效率就是生命。
Gemini 这个流程之所以强大,是因为它整合了:
- 视频分镜自动识别
- 图片关键帧自动提取
- AI Prompt 自动生成
- 视频要点自动分析
而你要做的,只是贴个链接,然后复制粘贴。甚至都不用懂太多技术,连我这个“剪辑半吊子”都能搞得定。
【Gemini 一键获取 YouTube 视频关键帧和提示词,轻松拆解对标视频】发布者:量子猫Q.Cat,转转请注明出处:https://www.qijiwiki.com/youtube-ai-frame-prompt-extraction/
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫